
Selected Projects
Scientifically-Interpretable Reasoning Network (ScIReN): Discovering Hidden Relationships in the Soil Carbon Cycle
Joint work with Haodi Xu, Feng Tao, Md Nasim, Marc Grimson, Lifen Jiang, Fengqi You, Benjamin Z. Houlton, Ying Sun, Yiqi Luo, Carla Gomes.

Soils have the potential to mitigate climate change by sequestering carbon from the atmosphere. Yet it is difficult to understand how carbon flows through the soil, leading to high uncertainties in future climate projections. While scientists have developed process-based simulations to model the carbon cycle, they contain numerous unknown parameters that govern key biogeochemical processes, which are traditionally set in an ad-hoc way that results in poor accuracy. We have developed techniques to integrate the scientific knowledge encoded in these process-based models with data-driven deep learning, to seamlessly learn parameter values across space [1]. On top of that, we developed Scientifically-Interpretable Reasoning Network (ScIReN), a fully transparent tramework that uses Kolmogorov-Arnold Networks to reveal functional relationships between environmental inputs and unobserved biogeochemical processes [2]. Our approach has excellent predictive accuracy, respects existing science, and allows us to infer unobserved biogeochemical processes and their functional relationships with environmental inputs.
For more information, see our paper, code, slides, or poster.
[1] Haodi Xu*, Joshua Fan*, Feng Tao*, Lifen Jiang, Fengqi You, Benjamin Z. Houlton, Ying Sun, Carla P. Gomes, Yiqi Luo. "Biogeochemistry-Informed Neural Network (BINN) for Improving Accuracy of Model Prediction and Scientific Understanding of Soil Organic Carbon." Under review at Geoscientific Model Development (GMD).
[2] Joshua Fan*, Haodi Xu*, Feng Tao*, Md Nasim, Marc Grimson, Yiqi Luo, Carla P. Gomes. "Scientifically-Interpretable Reasoning Network (ScIReN): Uncovering the Black-Box of Nature." To appear in AAAI 2026, AI for Social Impact track.
Monitoring Vegetation from Space at Extremely Fine Resolutions via Coarsely Supervised U-Net
Joint work with Di Chen, Jiaming Wen, Ying Sun, Carla Gomes
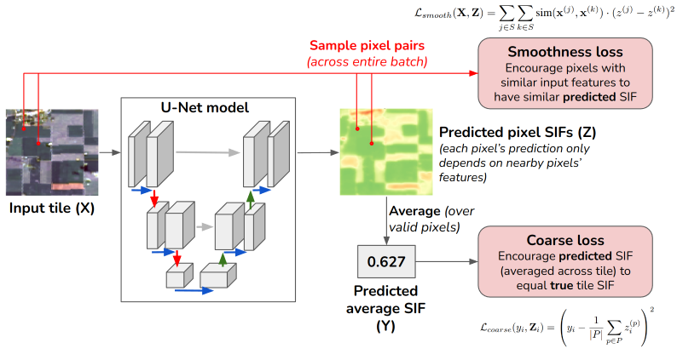
Solar-induced chlorophyll fluorescence (SIF) is a powerful tool to measure plant productivity from space. However, satellites can only measure SIF at a coarse spatial resolution. For example, we only know the average SIF of a 3x3 km tile, and cannot distinguish how individual farms are doing. To address this, we worked with plant scientists to develop Coarsely-Supervised Smooth U-Net (CS-SUNet). CS-SUNet takes in fine-resolution satellite imagery (Landsat), and predicts SIF for each 30m pixel, even though we only have labels at a much coarser resolution (3km). Even though the supervision is extremely weak, the model can produce accurate fine-resolution predictions thanks to strong regularization techniques (smoothness loss, early stopping) that encourage pixels with similar input features to have similar SIF predictions. Our method resolves fine-grained variations in SIF more accurately than existing methods.
For details, see this paper (IJCAI 2022):
[3] Joshua Fan, Di Chen, Jiaming Wen, Ying Sun, Carla Gomes. "Monitoring Vegetation from Space at Extremely Fine Resolutions via Coarsely-Supervised Smooth U-Net.” In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-22), AI for Good track, 5066-5072.
Interpretable Spatiotemporal Deep Learning for Crop Yield Forecasting
Joint work with Junwen Bai, Zhiyun Li, Kaitlyn Chen, Ariel-Ortiz Bobea, Carla Gomes
Forecasting crop yields accurately is crucial for food security and poverty alleviation. In collaboration with agricultural economists, we have developed deep learning techniques to forecast crop yields for US counties from a complex array of weather, soil, and management data. We use 1D CNNs to model temporal dependencies within a year, and a “county embedding” and graph neural network to model spatial structure [4]. We have adapted interpretability techniques such as Intergrated Gradients to temporal data to understand model predictions. Our model performs comparably to the USDA forecast in August and September. As a followup, we also developed a variant of the Transformer architecture, where attention scores depend purely on relative distance, and inject inductive biases such as locality and smoothness to handle the continuous nature of time series data.
[4] Joshua Fan*, Junwen Bai*, Zhiyun Li*, Ariel Ortiz-Bobea, Carla Gomes. "A GNN-RNN Approach for Harnessing Geospatial and Temporal Information: Application to Crop Yield Prediction.” In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-22), AI for Social Impact track, 11873-11881.
Aquaculture pond mapping with shape-aware contrastive learning
Joint work with Laura Greenstreet, Felipe Siqueira Pacheco, Yiwei Bai, Marta Eichemberger Ummus, Carolina Doria, Nathan Oliveira Barros, Bruce R Forsberg, Xiangtao Xu, Alexander Flecker, Carla Gomes.

Ecologists are interested in understanding the environmental impact of aquaculture expansion in the Amazon, yet there is little data on where fish farms are located. I am working with collaborators to create methods to detect fish farms from remote sensing imagery. Since there is little labeled data, I developed contrastive learning methods to leverage large amounts of unlabeled images to learn a better representation of each waterbody. This required designing novel augmentations to deal with multispectral images, emphasize the shape of waterbodies, and remove information from the irrelevant background landscape. Our learned representations significantly improved the model's ability to generalize to new regions with little data, overcoming challenging distribution shifts that threw off standard models. Some of this work was published in a KDD workshop paper [5], and we are continuing to work on making our methods more robust.
[5] Laura Greenstreet, Joshua Fan, Felipe Siqueira Pacheco, Yiwei Bai, Marta Eichemberger Ummus, Carolina Doria, Nathan Oliveira Barros, Bruce R Forsberg, Xiangtao Xu, Alexander Flecker, Carla Gomes. Detecting Aquaculture with Deep Learning in a Low-Data Setting." Fragile Earth workshop at KDD 2023. Long Beach, CA, USA.